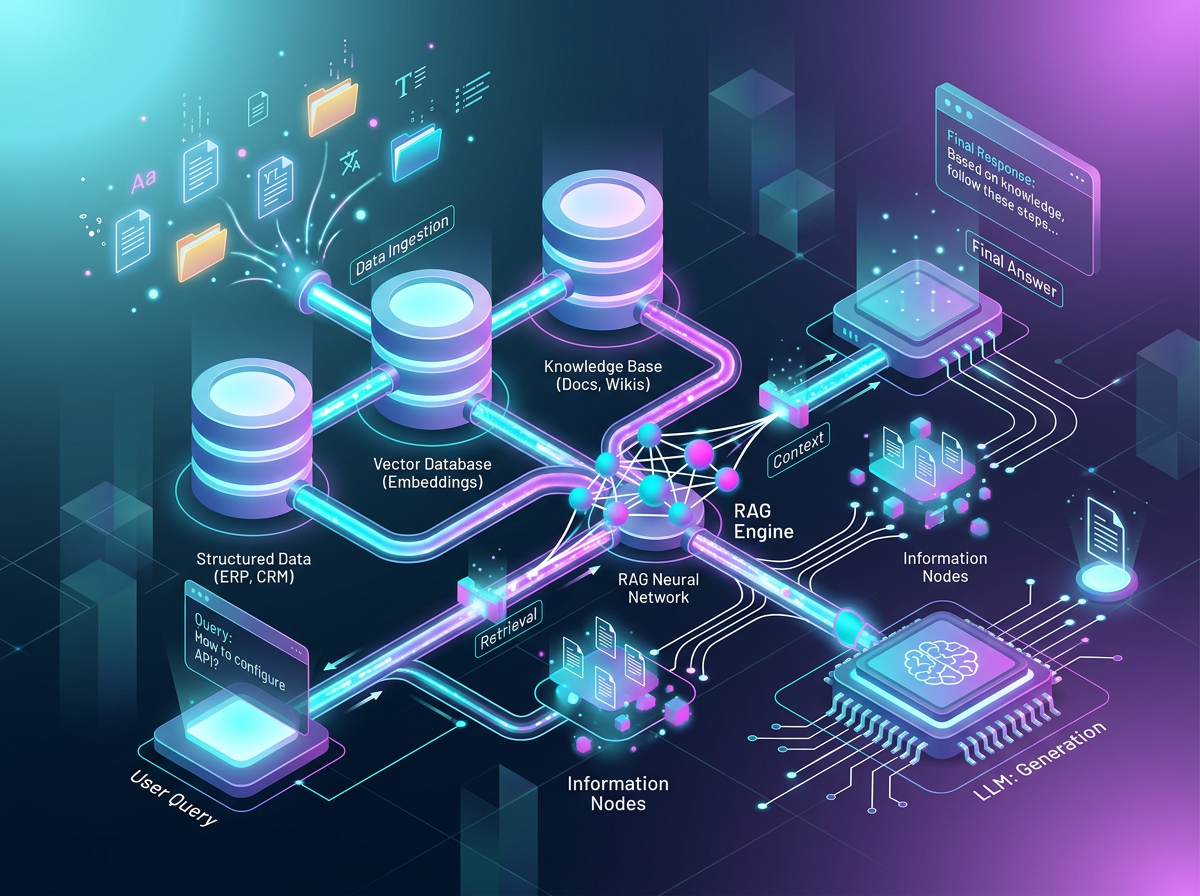
核心功能
模型量化
使用 GPTQ/AWQ 技术对模型进行 4bit/8bit 量化,大幅降低显存占用。
微调训练
基于 LoRA/QLoRA 技术,使用企业私有数据对基座模型进行高效微调。
推理服务
搭建高并发推理服务器,支持流式输出,兼容 OpenAI 接口格式。
安全审计
内置输入输出过滤机制,防止模型幻觉与敏感信息泄露。
技术架构
底层计算资源(GPU集群),基础模型层(Llama 3, Qwen, ChatGLM),微调框架(PEFT, DeepSpeed),推理引擎(vLLM, TensorRT-LLM)。
应用行业
金融风控医疗问诊法律咨询内部知识库
实施流程
01
数据准备
清洗企业私有数据,构建高质量指令集
02
基座选型
根据业务需求选择合适的开源基座模型
03
模型微调
进行全量或参数高效微调,注入领域知识
04
评测优化
使用测试集评估模型性能,持续迭代优化
05
私有化部署
在企业内网环境部署,交付推理 API
技术栈
vLLMLlamaIndexHuggingFaceDockerNVIDIA GPU
获取定制化方案
告诉我们您的需求,我们将为您提供专业的解决方案和报价